Built for AWS Polly TTS
What is AWS Polly?
AWS Polly is a "Text to Speech" web service. There are many out there - but this particular one integrates well with the technical needs of enabling Digital Humans to speak.
A didimo can be generated with AWS Polly compatibility.
You send AWS Polly a web request with the text input via the user (for a chatbot for instance) and Polly will return an audio file of the speech with a text file which is used to animate the lips to the correct shapes for each viseme at the correct time.
You can read up on AWS Polly Developer Documentation here
Didimo compatibility with AWS Polly
Didimo's facial blendshapes are built to be compatible with AWS Polly. You can generate a didimo with these additional blendshapes
See AWS Polly Viseme Mapping Table below
How to integrate AWS Polly?
More info can be found at:
- [AWS iOS Example ](https://docs.aws.amazon.com/polly/latest/dg/examples-ios.html
- AWS Android Example
Orientation
What is a Viseme?
A viseme represents the position of the face and mouth when saying a word. It is the visual equivalent of a phoneme, which is the basic acoustic unit from which a word is formed. Visemes are the basic visual building blocks of speech.
Each language has a set of visemes that correspond to their specific phonemes. In a language, each phoneme has a corresponding viseme that represents the shape that the mouth makes when forming the sound. However, not all visemes can be mapped to a particular phoneme because numerous phonemes appear the same when spoken, even though they sound different. For example, in English, the words "pet" and "bet" are acoustically different. However, when observed visually (without sound), they look exactly the same.
The above is an extract from the AWS Polly documentation - which you can read more here
What is a Phoneme?
A phoneme is the smallest unit of sound in speech. When we teach reading we teach children which letters represent those sounds. For example – the word ‘hat’ has 3 phonemes – ‘h’ ‘a’ and ‘t’.
What's the difference between a phoneme and viseme?
Phonemes are specific to sounds, visemes are specific to the shapes made by the mouth
| Type | Example |
|---|---|
| Phoneme | The word ‘hat’ has 3 phonemes – ‘p’ ‘e’ and ‘t’ |
| Viseme | The words "pet" and "bet" are acoustically different as such have different phonemes. However, when observed visually (without sound), they look exactly the same, which is the viseme. |
AWS Polly viseme mapping
You can generate a didimo with AWS Polly support that will contain the following 21 different phoneme blendshapes which follow the AWS Polly Specification

| AWS Polly Phoneme | Didimo Pose |
|---|---|
| phoneme_aa | 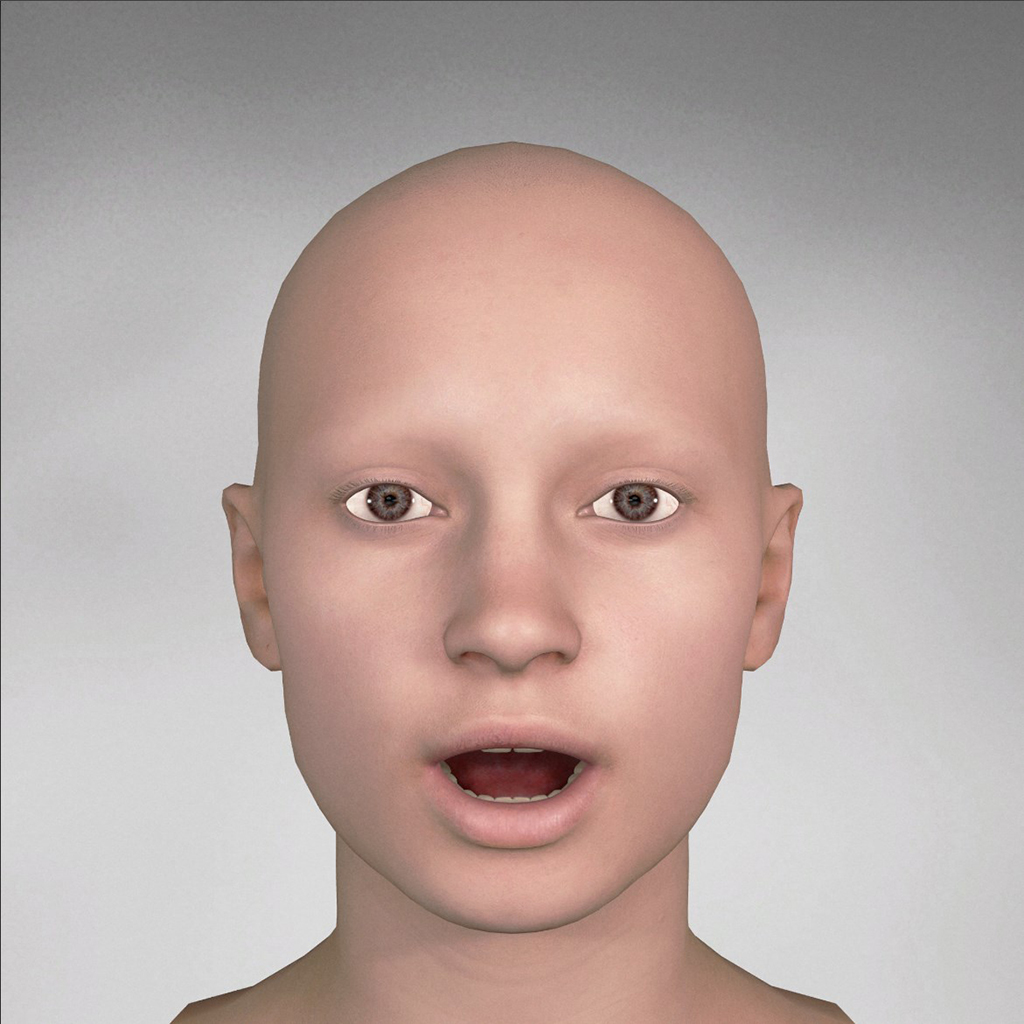 |
| phoneme_ae_ax_ah | 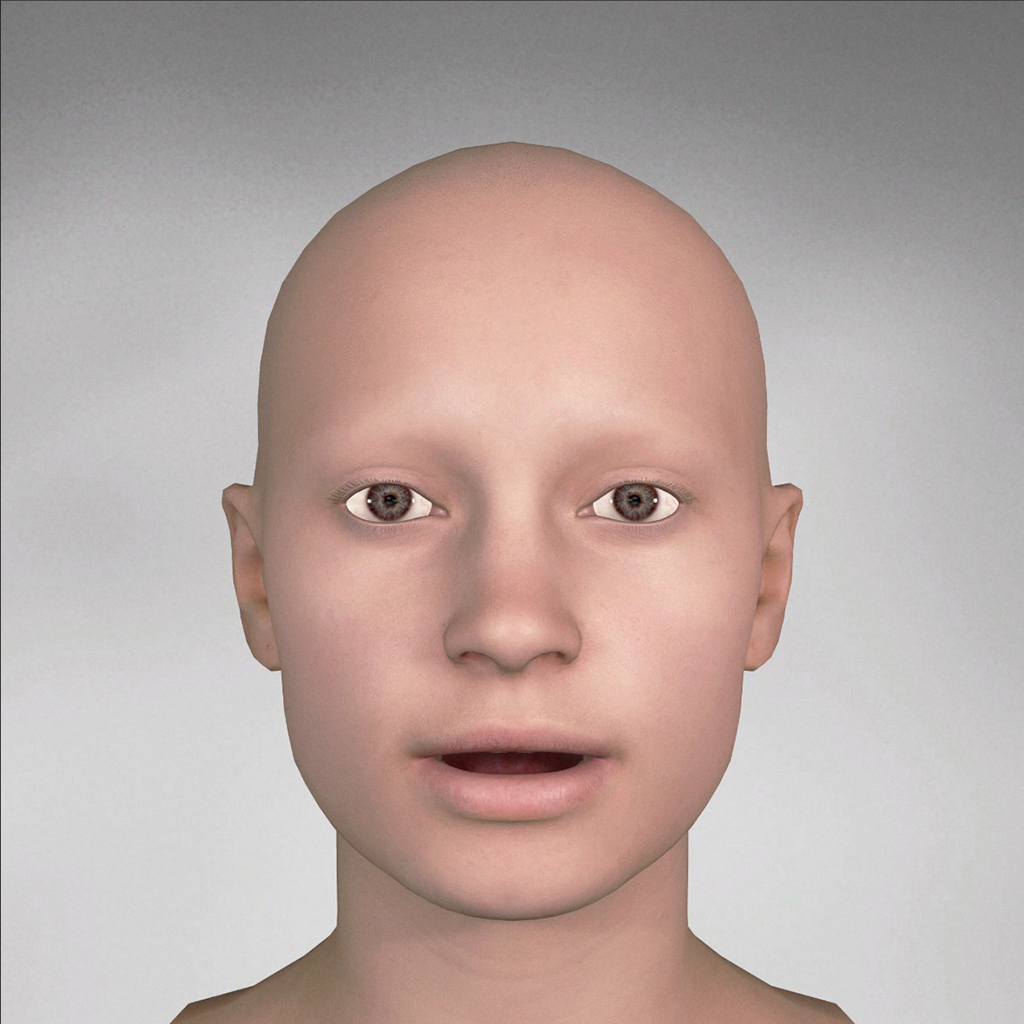 |
| phoneme_ao | 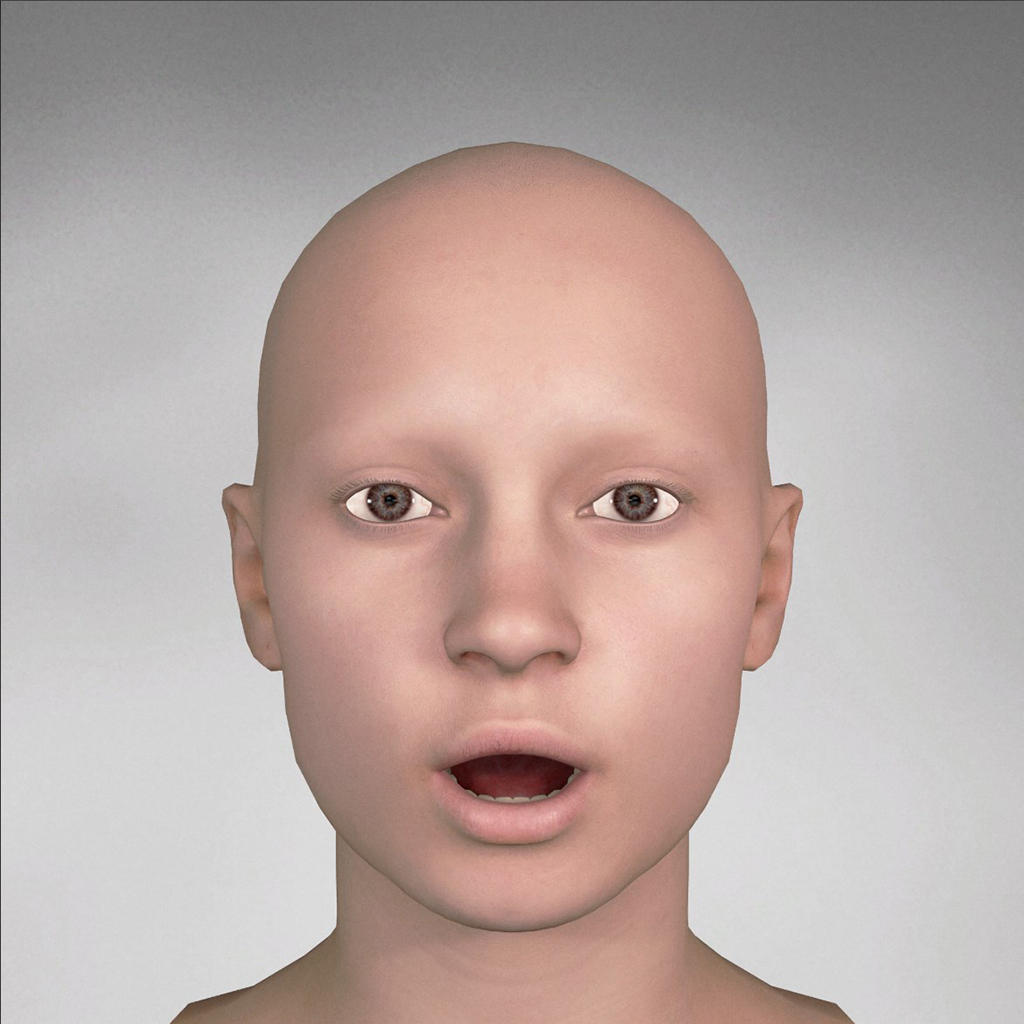 |
| phoneme_aw | 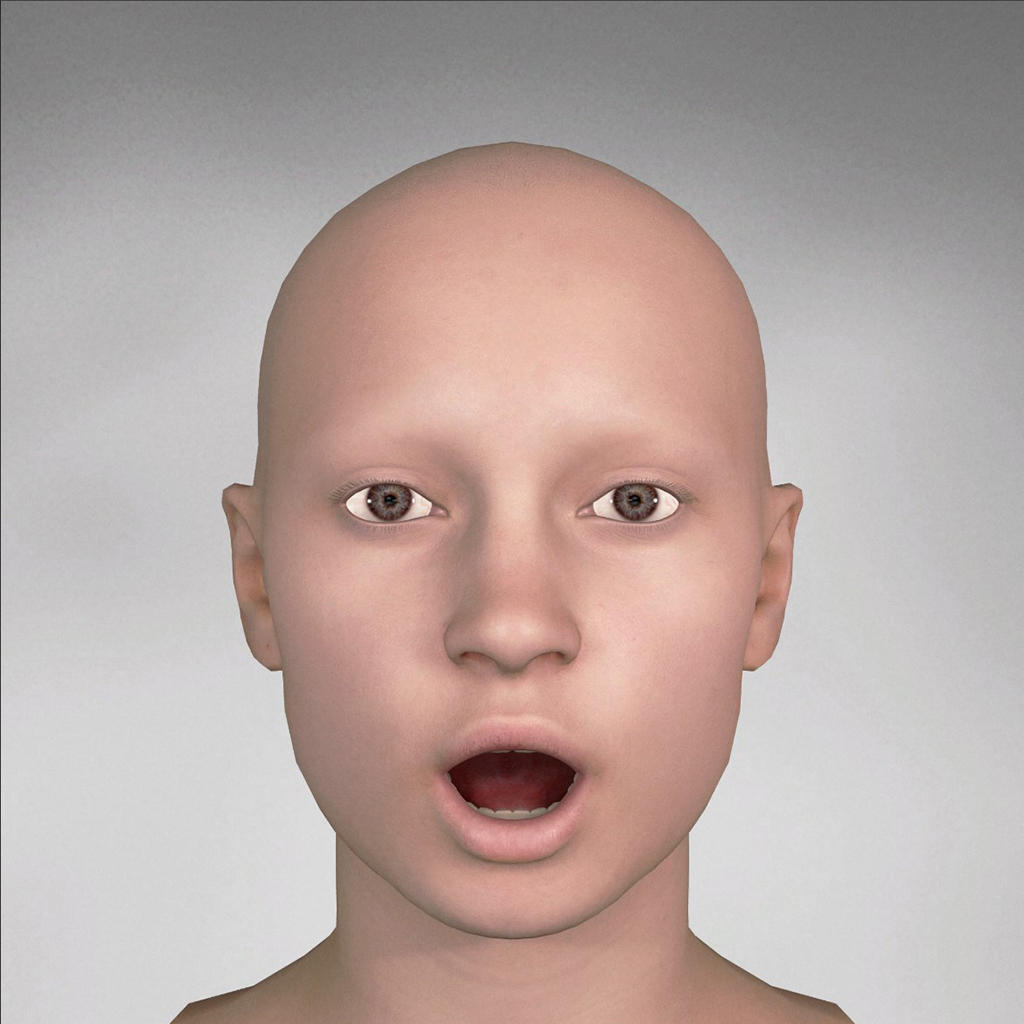 |
| phoneme_ay |  |
| phoneme_d_t_n |  |
| phoneme_er | 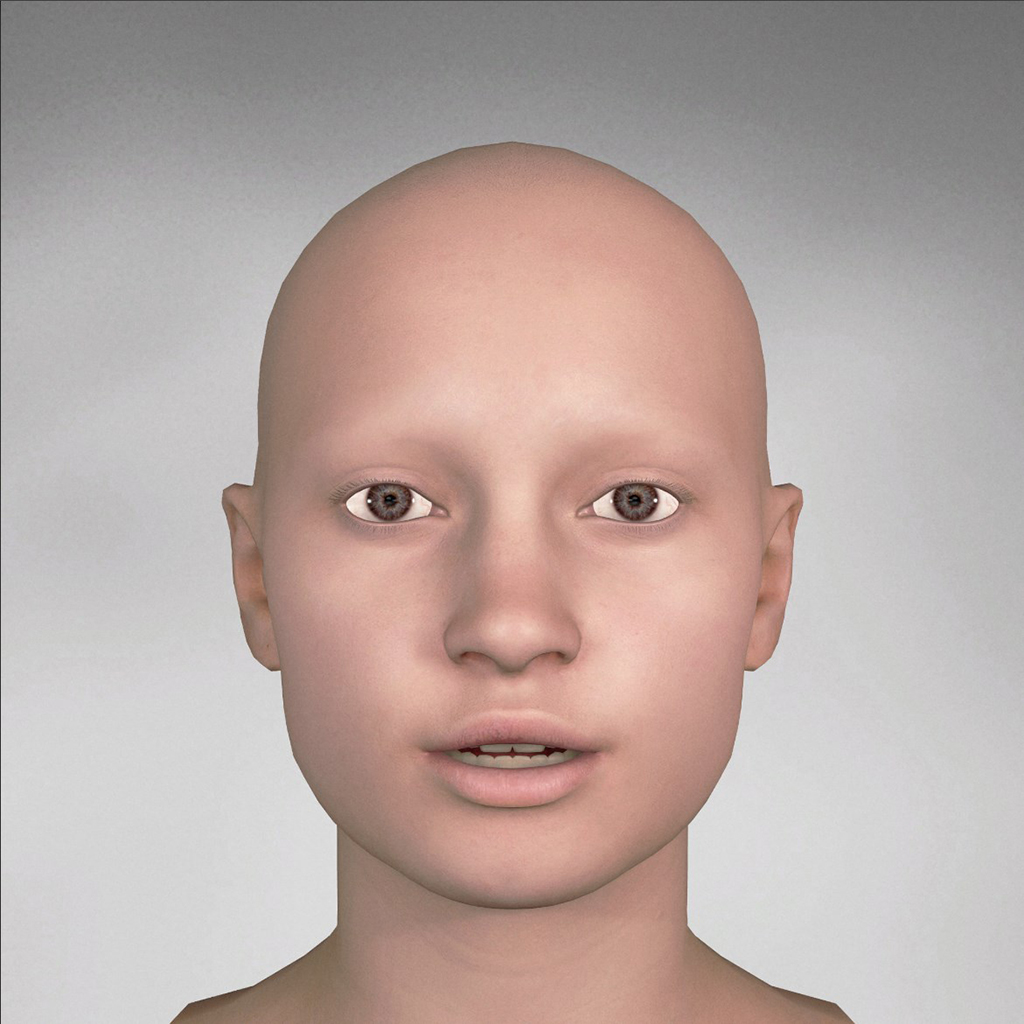 |
| phoneme_ey_eh_uh | 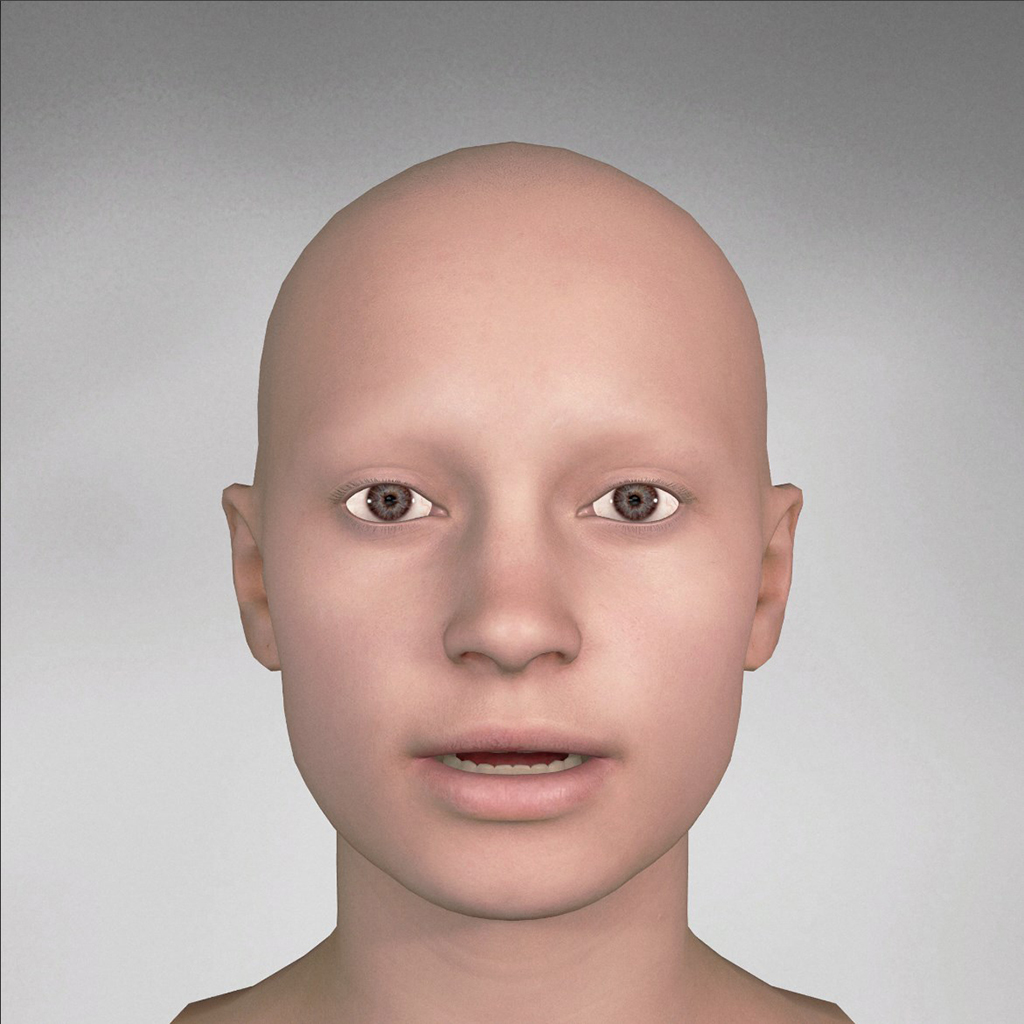 |
| phoneme_f_v |  |
| phoneme_h |  |
| phoneme_k_g_ng |  |
| phoneme_l |  |
| phoneme_ow | 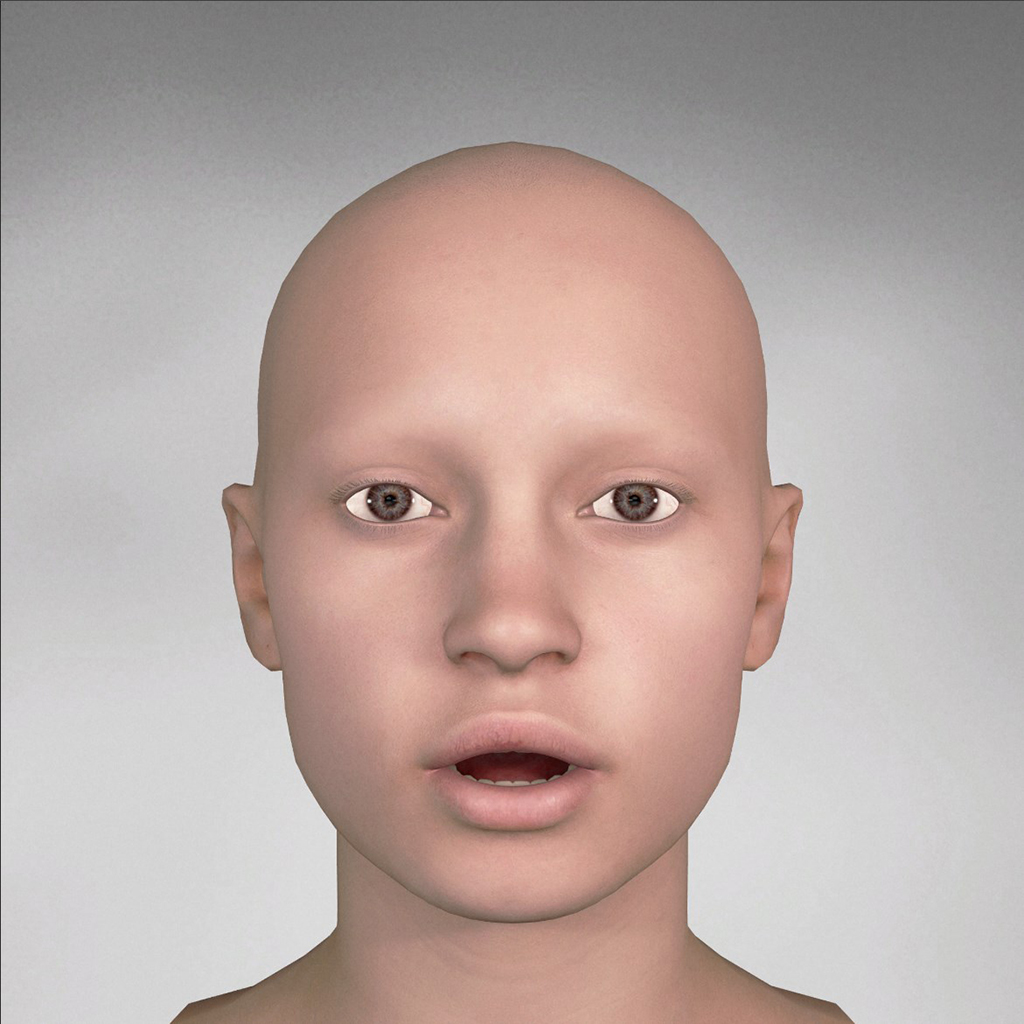 |
| phoneme_oy |  |
| phoneme_p_b_m |  |
| phoneme_r | 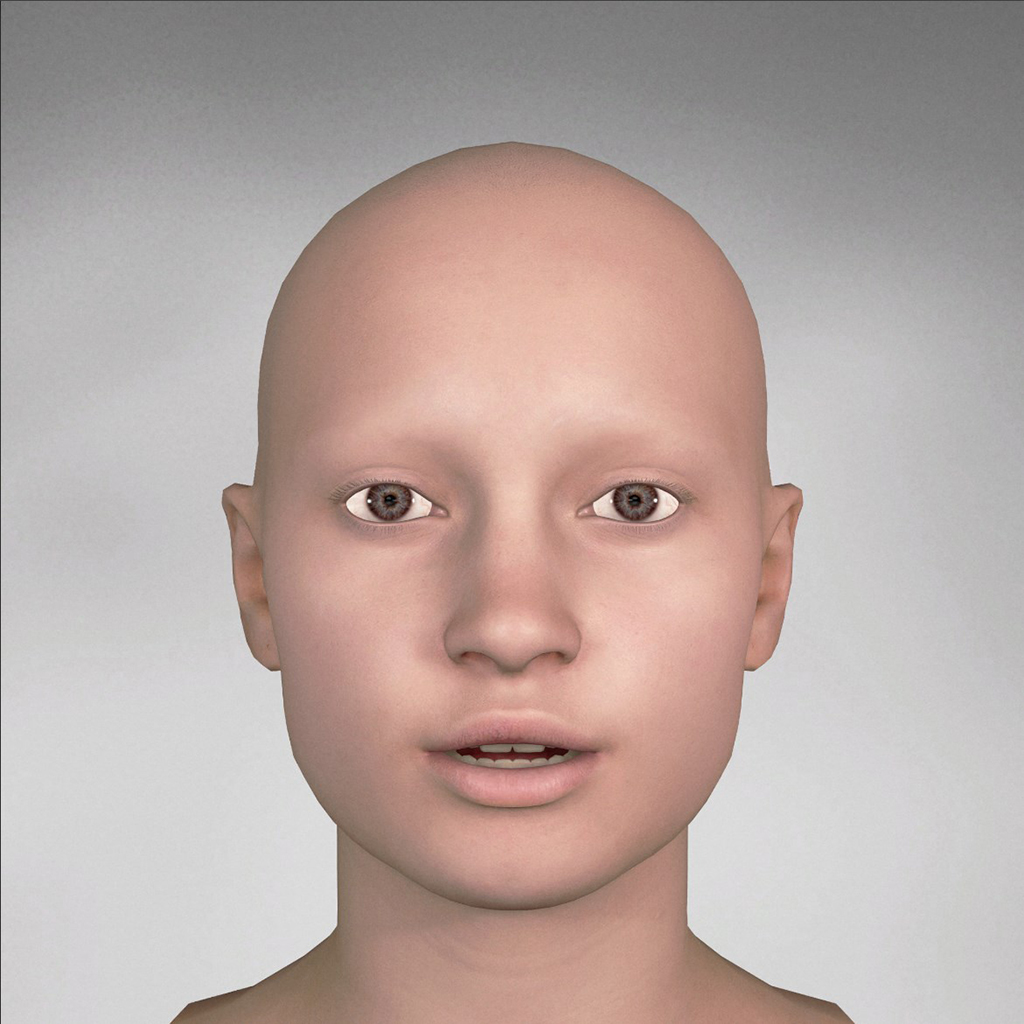 |
| phoneme_s_z |  |
| phoneme_sh_ch_jh_zh |  |
| phoneme_th_dh |  |
| phoneme_w_uw |  |
| phoneme_y_iy_ih_ix |  |
Updated 10 months ago